ツヨツヨのローカルLLMをつくる -3- ソフトウェア関連
これでハードウェアは出来上がった。
次が「リクラスAI」として使えるようにするためのソフトウェア設定。
基本的な条件としては
- テキストベースのAIインターフェイスを用意
- ClaudeやChatGPTなどのように使いやすさを重視
- ファイルアップロードにも対応する
- リクラスのWiFiエリア内で使えること
- 複数人で共有可能
- 屋外やリモートでも利用できる
いろいろと試行錯誤しながらインストールをしていった構成がこんなかんじ。
ハードウェア
| 項目 | 仕様 |
|---|---|
| CPU | AMD Ryzen 9 5900XT(16コア/32スレッド) |
| RAM | 64GB |
| GPU | NVIDIA GeForce RTX 3090 24GB |
| Storage | 500GB SSD(261GB使用 / 183GB空き、59%) |
| OS | Ubuntu 24.04.4 LTS(カーネル 6.17.0-23) |
| アクセス | Tailscale: |
AI インフラ層
Ollama(v0.23.2)
| モデル名 | サイズ | 用途 |
|---|---|---|
qwen3.6:35b-a3b-q4_K_M |
23 GB | 汎用メイン・Flux変換 |
qwen3-coder:30b |
18 GB | コーディング |
aider-coder-q30b |
18 GB | aider専用 |
coding-agent-q30b |
18 GB | Open WebUIエージェント |
dolphin3:8b |
4.9 GB | 軽量・高速 |
vLLM(Docker)
- イメージ:
vllm/vllm-openai:latest(31.8GB) - Gemma4 31B AWQ を vLLM で動かす構成(現在停止中)
- CUDA 13.2 / Driver 595.58.03
サービス層
Open WebUI(v0.9.5)
- デフォルトモデル:
coding-agent-q30b - Agent Mode: 有効
- MCP: 有効
- Context: 8192 / Temperature: 0.1
LLM Switcher
- Web UIでOllama / vLLM / ComfyUIを切り替えるコントロールパネル
- FastAPI製
Flux Studio
- 日本語→Flux.1英語プロンプト変換API(FastAPI)
- 使用モデル:
qwen3.6:35b-a3b-q4_K_M
Aider MCP Bridge
- MCPサーバー経由でaiderを呼び出す橋渡し
- 使用モデル:
aider-coder-q30b
Code Server(VS Code in Browser)
code-serverでブラウザからVSCode操作
いろいろ実験を繰り返している段階なので、ツッコミどころは色々ある(^_^;)
現在メインの推論モデル「qwen3.6:35b-a3b-q4_K_M」は商用サービスには届かないけどまずまずのレスポンス。でもハルシネーションが多いかな。
コーディング用の「qwen3-coder:30b」はレスポンスがいいので結構使えそう。
高性能なマシンだけあって、僕のような「逸般の誤家庭」では太刀打ちできないような環境ができた。
とはいえ、ClaudeやChatGPTのような商用サービスが日々磨いている機能性や使い勝手などにはまだまだ届かないという点が多いと思った。
そのへんは別記しよう。
画像生成についてはかなりすごい性能を感じているけれど、テキスト系の生成AIと共存するほどのVRAMに余裕がないのでBackend Switcherという仕組みを作って切り替えられるようにした。
だから通常は使えないようにしている。
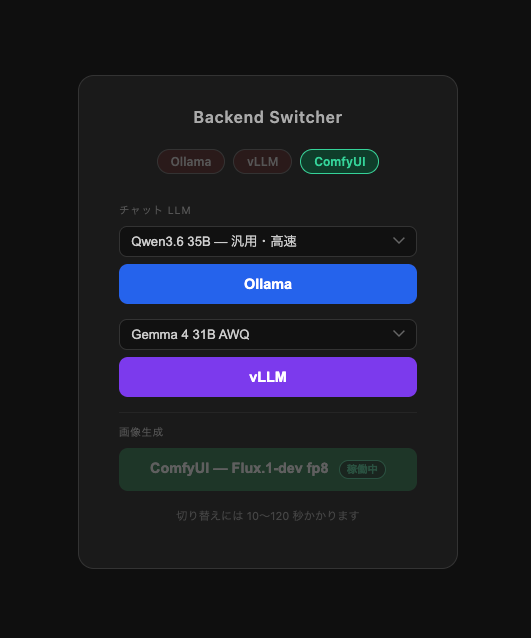
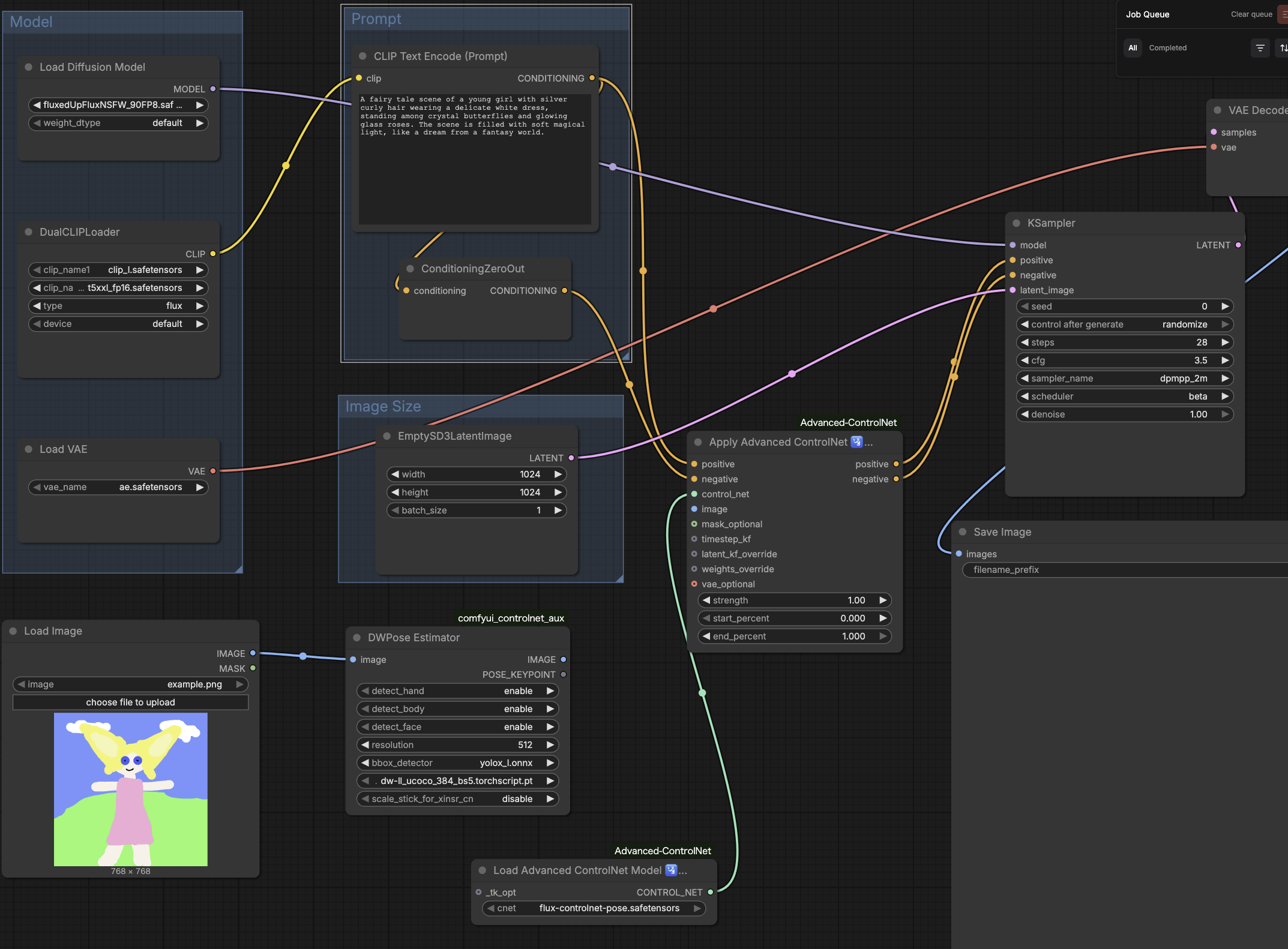
試行錯誤した限りでは画像生成はきれいなものが出力できるけれど、設定やら導入するモデルやLoraモデルなどの選定、そのほかパラメーターが多すぎて難しい。
まぁ、できるという程度にしておこう。
まだ続く